Parameter Testing
There are many factors that come into play in determining the performance of a classification task: for example, tuning parameters on the classification algorithm, the use of outlier detection, feature selection and feature generation can all affect the end result. In general, it is hard to know a priori which combination of parameters will be the optimal one for a given data set or class of problem, and testing several possibilities of parameter values is the only way to better understand their influence and find a better fit.
The number of combined possibilities on how to tune a classification task however grows fast and testing them manually can become tedious very quickly. This is where parameterization can help. On RapidMiner, under Meta -> Parameter operators, we'll find several parameter optimization schemes:
- Parameter iterator
- Grid Parameter Optimization
- QuadraticParameterOptimization
- EvolutionaryParameterOptimization
We would like to test the effect of feature selection to our previous sentiment classification experiment. Recall that our word vector for the sentiment classifier generated some 2012 features based on unigram terms found in the source documents, after removal of stop words and stemming. Now, we can apply a scheme for filtering out uncorrelated features before we train the classifier algorithm.
Step 1 - Attribute Weighting and Selection
RapidMiner comes with a wealth of methods for performing feature selection. We extend the sentiment classification example by using a weighting scheme to attributes on the feature vector. Then, the top K highest weighted attributes (which we hope are the top most correlated to the labels) are chosen for training a classifier algorithm.
We introduce a pre-processing step to the training algorithm by introducing 2 operators:
- InfoGainRatioWeighting - Calculates numeric weights for each attribute based on information gain in relation to the positive/negative labels.
- AttributeWeightSelection - Filters attributes based on their associated numeric weights. This operator will take as input the example set containing data from our feature vector, and the result of applying the previous InfoGain weights to the example set. There are several criteria to choose from, and we will use the "top k" most relevant attributes.

Fixing Random Seed
By default, RapidMiner will use a dynamic seed whenever randomization is needed, for instance, when sampling the data set for cross-validation. To make sure our experimental results are repeatable on every run, we can fix our random seed by assigning it a specific value. This should be done on the "root" and "cross validation" operators.
Right now the project is ready to run. Lets see how it fares by leaving say, only the top 100 features according to the weighting scheme and applying those features to train the same classifier algorithm as before. Right click on the InfoGainRatioWeighting operator and add a "BreakPoint After" stop. When running the experiment, we can see the state of the execution process right after this step has run. At that stage, the attribute weights have been created. We can have a look at which ones were given the highest weights, giving an indication of the most correlated features to the positive or negative sentiment label:

In this weighting scheme we notice some familiar terms we would expect to correlate with a good or bad film review. Terms such as "lame", "poorly" and "terrific" score highly. Also, we notice some more unexpected predictors, such as the term "portray", which appears to be relevant to classification on the domain of films.

Once the experiment is complete, we see that in this data set, reducing the total number of features from 2012 to just 100 yielded an average accuracy of 81%. This is worst than having the experiment run with all the features (84.05% in our previous experiment), suggesting pruning the data set to only 100 features might be too severe and could be leaving out many terms that are good predictors. The question then is: is removing potentially uncorrelated features of any benefit to sentiment classification in this experiment?
Step 2 - Parameterization
We'll apply the GridParameterOptimization operator to test from a list of potential parameter combinations, based on accuracy criteria. The operator is added to the project just after the data set read step (ExampleSource), and the remainder of the operators are included as part of its subtree.
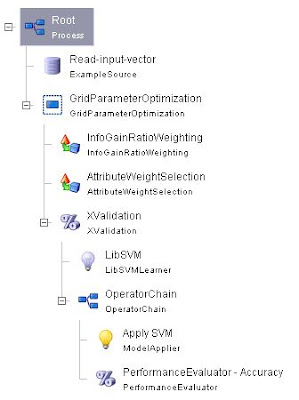
From this point on, the parameters affecting the behavior of the operators can be added to the parameter search scheme. Determining which combination works best is based upon results obtained from the "Main Criterion" in the Performance Evaluator operator. In our case, the criteria is accuracy. The operator is configured by selecting attributes we wish to test, and what values each attribute will take. In our example the experiment compares the results for selecting the k topmost relevant features according to seven different values of k:
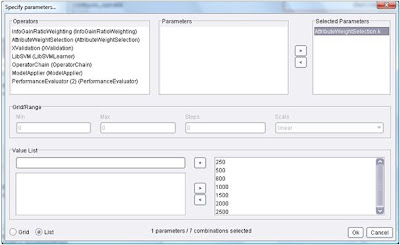

From this point on, the parameters affecting the behavior of the operators can be added to the parameter search scheme. Determining which combination works best is based upon results obtained from the "Main Criterion" in the Performance Evaluator operator. In our case, the criteria is accuracy. The operator is configured by selecting attributes we wish to test, and what values each attribute will take. In our example the experiment compares the results for selecting the k topmost relevant features according to seven different values of k:

In our experiment, the average classification accuracy improved to 85.80% when using k = 800 topmost weighted features. This is better than our original baseline of 84.05%, and has the added benefit of using less features, therefore reducing the footprint necessary to train and run the algorithm. Not bad for a day's work, considering the tool did most of the work :-).

Further improvements could naturally be obtained by testing k at more granular increments, or including other factors such as support vector machine parameters. It is important however to bear in mind that adding more testing instances will result in a much larger search space, thus increasing the time needed to tune the experiment. For instance, searching for 50 values of k on the feature selection approach, combined with 10 possible values for tuning parameters on the classifier would result in 50 x 10 = 500 iterations. The numbers can add up quickly.
Other Approaches
The GridParameterOptimization operator is quite straightforward: just iterate over a list of parameter combinations and retrieve the one tha optimizes a particular error function, in our case accuracy. Finding the best combination of parameters relates to a more general problem of search and optimization, and lots of more sophisticated strategies have been proposed in the literature, some of which are also present in RapidMiner such as the QuadraticParameterOptimization operator, and the EvolutionaryParameterOptimization which implements a genetic algorithm for searching parameter combinations.

Other Approaches
The GridParameterOptimization operator is quite straightforward: just iterate over a list of parameter combinations and retrieve the one tha optimizes a particular error function, in our case accuracy. Finding the best combination of parameters relates to a more general problem of search and optimization, and lots of more sophisticated strategies have been proposed in the literature, some of which are also present in RapidMiner such as the QuadraticParameterOptimization operator, and the EvolutionaryParameterOptimization which implements a genetic algorithm for searching parameter combinations.
Further Reading
Feature selection applied to text mining has been investigated by a number of authors, and a good overview of the topic can be found in the work of Sebastiani, 2002 (retrievable here).
Finally, an approach that uses feature selection techniques to the problem of sentiment classification can be seen in the work of Abbasi et al, 2008.
Wow, thanks for those two great RapidMiner tutorials. They really helped me a lot! Thanks for your efforts and keep up the good work.
ReplyDeleteBest,
Marcel
This comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis blog is so useful! Please post again, its been too long :)
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteMany thanks to the person, who wrote this post - it helped me out a lot :-)
ReplyDelete